
Rule-based/data-centric design
Focus on the domain, not the implementation

If we’re being honest with each other, then the vast majority of software out there is at best mediocre crap. It’s not just that the majority of it serves no real purpose — or is even destructive — it’s that it is often so poorly conceived and executed.
A key reason for this is that the wrong individuals are doing the work.
Data and presentation are orthogonal concerns
Data has a shape. A boolean is a boolean and a string is a string. A list is ordered. A set is an unordered group of unique values. A map is a group of labeled values whose labels form a set. And so on.
We can get much more specific, something that most type systems fail miserably at. Why is that? Idris is a start, but why stop there?
Where is the trilean — a datum that can be true, false, or indeterminate? When I specify a string type, why can’t I include minimum and maximum lengths, or which characters are allowed, or matching patterns (regular expressions) as part of the type declaration?
Or when specifying a list (as, for example, an array), why can’t I specify a sorting function and a maximum length as part of the type?
Hell, why aren’t there already datatypes for such common data as phone numbers, street addresses, etc.? Sure, they are all over the place, but all the more reason to build a datatype once that only permits valid values.
Why is our ability to schematize data still in the fucking Stone Age?
Beats me. I guess no one cares.
Separating concerns properly
Let’s say, hypothetically, that we can describe our data properly. So let’s say that a given datum, x, can hold one or more members of an enumerated set, but with further restrictions, such as “cannot contain both a and b” or “if contains c, then must also contain e and f”.
Nice. Now we have two concerns to address:
How do we collect (and validate) that datum?
How do we present that datum to the user?
It should be obvious (but probably isn’t) that there are numerous ways to view or collect these data.
On the view side, we must consider the medium. Is it to be printed? Black and white, grayscale, or full color? Is it to be displayed on a screen? Is it to be read aloud by a screen reader? Is it to be consumed by a machine?
There are multiple media, but it’s a relatively small and known set, no?
How can we display (or include) the underlying shape of the datum? If the value includes a, how can we indicate that because it includes a, it cannot include b?
Perhaps we have a display that shows a underlined or bold in one column, and then b in an adjoining column struck through (b) and with an arrow from a to b labeled “precludes”. Or if read aloud, is read as “a” followed by, sotto voce, “precludes b”. Or perhaps this is configurable via a “verbosity” setting, or even a more specific setting such as “expose precluded values”.
You get the point, I hope.
On the input side, suppose you are selecting values from a list of enumerated values. When you select “a” then “b” is struck out and, perhaps on pointer hover, a tooltip appears saying “precluded by a”.
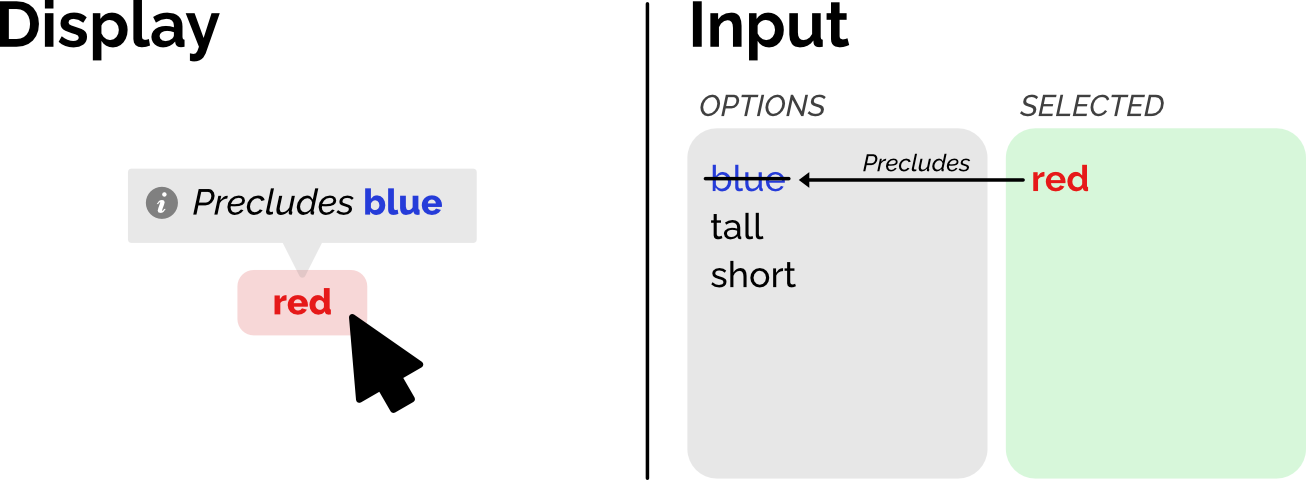
The point is, we can come up with best practices — tested thoroughly on real users — for how to display and/or collect these data as determined by the data shape.
Stop thinking in widgets!
When a developer is creating, for example, a form, most often they do not think in terms of the data shape. They think in terms of the widget they will use for it.
For example, they have a boolean value such as isAuthorized. They might immediately think of a checkbox. Or, if the common practice for their interfaces is to use switches, a switch.
The dev probably has a component library with widgets such as Checkbox and Switch. So they choose one.
This is one of the problems with “component libraries” (there are many): they all name their components by the widget type rather than by the data shape it represents.
I do this differently. When I build components for reuse on a project (note: I strenuously avoid using imported component libraries unless forced to by the client), I do not name them Checkbox or Switch or Combobox. I name them by the datatype they expose.
Components by data shape
I have a Boolean component, a Trilean component, a Member component (for choosing one from an enumerated list), a Subset component (for choosing some from an enumerated list), etc.
The Boolean component might display as a single checkbox. But it might also be a switch, two radio buttons, or a select with two values (one preselected). The Trilean component is similar, but with an indeterminate value option. And so on.
So which gets used? That is determined using rules at a global level.
For example, suppose I have a datum that is a subset of some enumerated set. This could be displayed as columns of checkboxes, or a multi-select, or some kind of tag chooser, etc.
So my Subset rule might state that for sets of 15 items or fewer, display checkboxes in up to three columns of five values. But for more than 15 items, switch to a multi-select widget. Or better, one of those widgets with the enumerated values on the left, and the selected values moved to a column on the right.
The final choice of widget should be based on good UX and thorough user testing, and once that rule is set, then it should take a written consent before the dev can violate it in a given, specified circumstance.
Data-driven UIs
This is the secret behind the “data-driven UI”. The data store must include a schema capable of encoding the business rules for the data as part of the “datatype”. It is absurd to have fields in your database typed as, say “VARCHAR(36)” with no hint whatsoever as to what that data really is. Seriously?
Whether the database schema includes this data and is used to generate the API, or the API defines the schema which is used to create the database, I really don’t care. I’ve done it both ways. What is important is that there is a single source of truth.
And this single source of truth can determine not only the database schema and the API/business layer/logic, but also the presentation — the interface.
The query to the back end should never return merely primitive data. It is not enough to know that this is a string and that is an integer and that over there is a boolean. Truth is, many queries don’t even provide that much data. It is left to the front end to encode what datum “a” is.
Now we have the potential for conflict. The database thinks that x is a string, but the business logic thinks that it’s a number, and then the front end treats it as a boolean. WTF?
Obviously, that’s an extreme case, but why is it even in the realm of possibility?
We can handle display as well
If we have properly encoded the real shape of our data, then our component can handle both collection and display.
For example, suppose I have a string value that represents a URL. This is a simple algebraic type that we could specify relatively precisely. Our component could even do a HEAD or OPTIONS request and determine whether the resource is available at runtime.
So we have a Url component. When isMutable is set to false, then it displays as a link using the <a> element. It should know whether the link is internal or external, so it can automatically set rel=”external” and the stylesheet can automatically indicate that in some manner.
Perhaps it has a showStatus property that, when true, does an OPTIONS request after which the stylesheet can again indicate whether the resource exists and is accessible (maybe it requires login). That might be nice to know.
And I don’t have to hard code “(requires log in)”. I can simply use CSS ::after pseudo-element to add it, and then only when the OPTIONS request returns a 401 Unauthorized status code. So if I’m already logged in, it does not display the warning.
And all this done automatically in real time.
If isMutable is set to true, then there are lots of options. Which will be used can be set globally or locally. Rule-based, right?
Maybe it displays as a link, but with an “Edit” button. Or maybe it automatically displays as an editable Email input with a “Follow Link” button. Or whatever. That’s up to the UX engineer and the designer based on user testing. It should not be up to the dev.
It’s automatic
In fact, once we have created the Url component, there is no need to build it again or even to use it. All that is necessary is to include that field in the query results. Those results can be sent to an automated renderer, which selects, groups, and configures the correct components for the data form/display based on the query result and the encoded rules/schema.
Everything on every page is data.
It’s all data. Every link, every paragraph, every list, every image, everything. If it is properly described in the data store, whether that is an RDMBS, the file system, or some kind of graph database is irrelevant. When the front-end does the HTTP request (or the XmlHttpRequest), the data should be returned with all the information necessary for the UI to know how to display it.
That includes what further actions are possible (think HATEOAS). Is this datum updatable? Then include the query that will update it. Is it deletable? Then include the query that will delete it.
And the back end knows, based on the business logic, whether you have the authorization to do so or not. If not, the queries are not included, hence the UI does not offer that option. Simple.
Now a single front-end application, generic except that it encodes the design system of the enterprise (as CSS and the ruleset, but both can also be query results or can be combined into a federated query) can be given a simple query, or even just an API URL, and can build the entire interface from the query result.
And this could be done server side (with caching) but also client side when necessary. Just like SSR/SSG now.
Change the the rules, the data shapes, or the data itself, and the UI automatically adapts instantly to the new “truth”. Your data source becomes the one-stop shop for your entire application. Or for multiple applications for the same organization.
How to encode all this?
But how do we encode all this? We have data shapes (types) with very specific limitations. We have business rules and logic that relate these types to each other (and perhaps to the external world, such as temporal or geographical constraints or authentication/authorization), we have our design system which includes our branding and all our UX IP. How could we possibly control all this in one place?
It’s called an ONTOLOGY
What is an ontology in programming? Wikipedia describes it thus:
In computer science and information science, an ontology encompasses a representation, formal naming, and definition of the categories, properties, and relations between the concepts, data, and entities that substantiate one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of concepts and categories that represent the subject.
There are various ways to encode an ontology. These include RDF (RDFS), OWL, SHACL, and more. There is also a query language for ontologies, SPARQL. And there are special databases — graph databases — designed to store ontological data. These are called triple stores because the data is generally stored in the form of “triples”: subject, predicate, object (some allow a fourth value for graph). Kind of like English.
An open-source triple store you can use for experimenting is Apache Jena/Fuseki. There are also online tools, such as this SHACL playground.
These are all part of an approach to software development called “data-centric architecture”. (Note: not the same as “database-centric architecture”.) At the enterprise level, as usual, this all gets fiendishly complex very quickly. But it needn’t be that way.
As an advocate of “exitprise”, I recommend getting over our obsession with incidental complexity and focusing on keeping things as simple as possible. Or, as Guillermo Rauch once said to me, “never write a line of code until you have to”.
I have my own project — “sitebender” — moving at a snails pace to implement a data-centric application based on SHACL ontologies, SPARQL queries, and a triple store, the idea being to define the domain and application once in the data store, and then to generate the entire application — front to back — from that ontology.
It is moving very slowly as I’m one person and have much on my plate, but I will post updates here as I go along.